Hallo Readers.
kali ini kita akan belajar bagaimana mencari FASTA dalam situs berbasis science seperti ncbi.nlm.nih.gov
FASTA
A sequence in FASTA format begins with a single-line description, followed by lines of sequence data. The description line (defline) is distinguished from the sequence data by a greater-than (“>”) symbol at the beginning. It is recommended that all lines of text be shorter than 80 characters in length. An example sequence in FASTA format is:
>gi|129295|sp|P01013|OVAX_CHICK GENE X PROTEIN (OVALBUMIN-RELATED) QIKDLLVSSSTDLDTTLVLVNAIYFKGMWKTAFNAEDTREMPFHVTKQESKPVQMMCMNNSFNVATLPAE KMKILELPFASGDLSMLVLLPDEVSDLERIEKTINFEKLTEWTNPNTMEKRRVKVYLPQMKIEEKYNLTS VLMALGMTDLFIPSANLTGISSAESLKISQAVHGAFMELSEDGIEMAGSTGVIEDIKHSPESEQFRADHP FLFLIKHNPTNTIVYFGRYWSP
Blank lines are not allowed in the middle of FASTA input.
Sequences are expected to be represented in the standard IUB/IUPAC amino acid and nucleic acid codes, with these exceptions: lower-case letters are accepted and are mapped into upper-case; a single hyphen or dash can be used to represent a gap of indeterminate length; and in amino acid sequences, U and * are acceptable letters (see below). Before submitting a request, any numerical digits in the query sequence should either be removed or replaced by appropriate letter codes (e.g., N for unknown nucleic acid residue or X for unknown amino acid residue). The nucleic acid codes supported are:
A adenosine C cytidine G guanine T thymidine N A/G/C/T (any) U uridine K G/T (keto) S G/C (strong) Y T/C (pyrimidine) M A/C (amino) W A/T (weak) R G/A (purine) B G/T/C D G/A/T H A/C/T V G/C/A - gap of indeterminate length
For those programs that use amino acid query sequences (BLASTP and TBLASTN), the accepted amino acid codes are:
A alanine P proline B aspartate/asparagine Q glutamine C cystine R arginine D aspartate S serine E glutamate T threonine F phenylalanine U selenocysteine G glycine V valine H histidine W tryptophan I isoleucine Y tyrosine K lysine Z glutamate/glutamine L leucine X any M methionine * translation stop N asparagine - gap of indeterminate length
NOTE:
¹ The degenerate nucleotide codes in red are treated as mismatches in nucleotide alignment. Too many such degenerate codes within an input nucleotide query will cause blast.cgi to reject the input. For protein queries, too many nucleotide-like code (A,C,G,T,N) may also cause similar rejection.
² For protein code, U is replaced by X first before the search since it is not specified in any scoring matrices.
³ blast.cgi will not take “-” in the query. To represent gaps, use a string of N or X instead.
Langkah pertama buka situs ncbi.nlm.nih.gov
Halaman awal yang akan tampil adalah seperti gambar dibawah ini, selanjutnya All Database diubah menjadi nucleotide

Gambar halaman awal
Langkah selanjutnya ketik hormon yang akan dicari dan spesiesnya
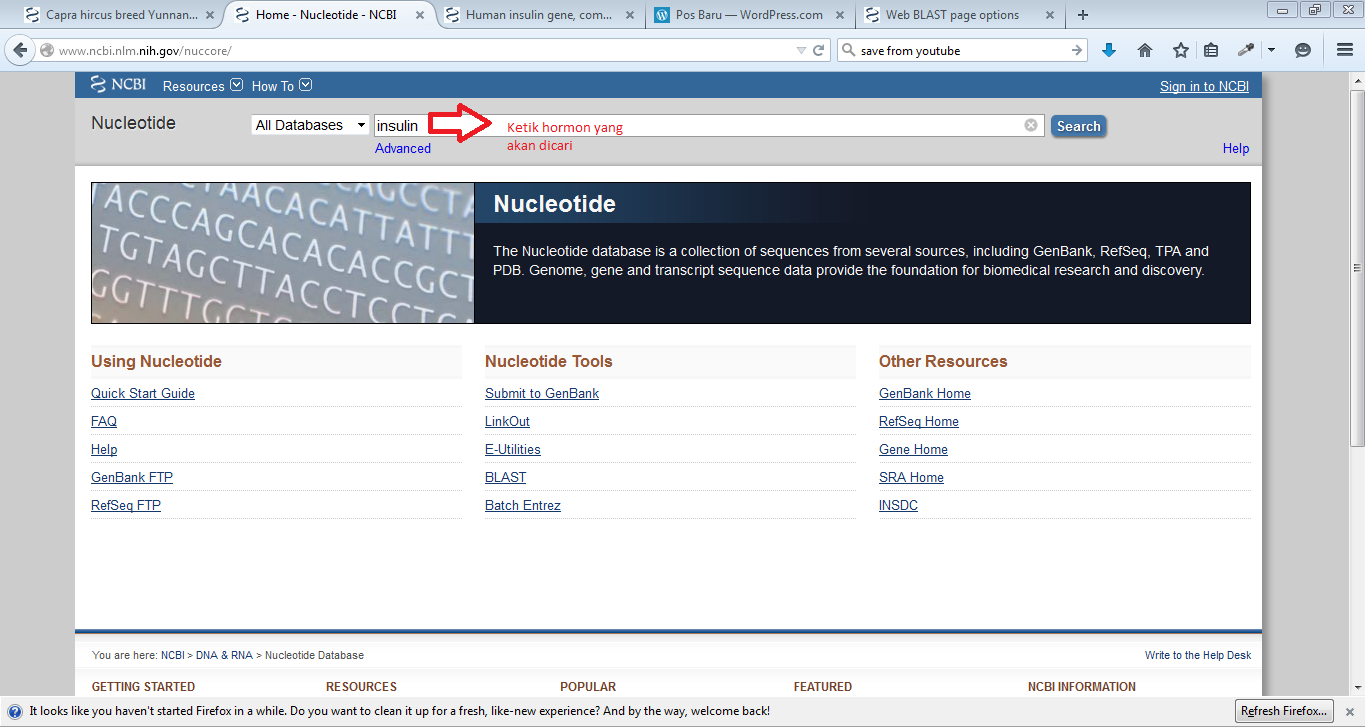
Gambar tampilan searching hormon
Kemudian akan terlihat

Tampilan FASTA pada “Human insulin gen” pada gambar terlihat rangkaian basa nitrogen yang spesifik sesuai dengan spesies.

Gambar “Human insulin gen”
Tampilan FASTA pada “Octodon Degus Insulin mRNA)  Tampilan FASTA pada “giberelin sunflower”
Tampilan FASTA pada “giberelin sunflower”

Tampilan FASTA pada Black Goat

Tampilan FASTA berupa rangkaian basa nitrogen yang berbeda-beda sesuai spesies masing-masing. sekian terimakasih
